什么是Pod?
Pod是kubernetes中你可以创建和部署的最小也是最简的单位。映射到docker容器上,一个pod是一组密切相关的容器,只是被k8s用pod概念在逻辑上组织在了一起。同一个Pod中的容器会自动的分配到同一个 node 上。同一个Pod中的容器共享资源、网络环境和依赖,它们总是被同时调度。
Pod资源对象是一种集合了一个或多个应用容器、存储资源、专用ip、以及支撑运行的其他选项的逻辑组件。Pod其实就是一个应用程序运行的单一实例,它通常由共享资源且关系紧密的一个或2多个应用容器组成。
Kubernetes的网络模型要求每个Pod的IP地址同一IP网段,各个Pod之间可以使用IP地址进行通信,无论这些Pod运行在集群内的哪个节点上,这些Pod对象都类似于运行在同一个局域网内的虚拟机一般。
我们可以将每一个Pod对象类比为一个物理主机或者是虚拟机,那么运行在同一个Pod对象中的多个进程,也就类似于跑在物理主机上的独立进程,而不同的是Pod对象中的各个进程都运行在彼此隔离的容器当中,而各个容器之间共享两种关键性资源:网络和存储卷。
网络:每一个Pod对象都会分配到一个Pod IP地址,同一个Pod内部的所有容器共享Pod对象的Network和UTS名称空间,其中包括主机名、IP地址和端口等。因此,这些容器可以通过本地的回环接口lo进行通信,而在Pod之外的其他组件的通信,则需要使用Service资源对象的Cluster IP+端口完成。
存储卷:用户可以给Pod对象配置一组存储卷资源,这些资源可以共享给同一个Pod中的所有容器使用,从而完成容器间的数据共享。存储卷还可以确保在容器终止后被重启,或者是被删除后也能确保数据的持久化存储。
一个Pod代表着某个应用程序的特定实例,如果我们需要去扩展这个应用程序,那么就意味着需要为该应用程序同时创建多个Pod实例,每个实例都代表着应用程序的一个运行副本。而这些副本化的Pod对象的创建和管理,都是由一组称为Controller的对象实现,比如Deployment控制器对象。
当创建Pod时,我们还可以使用Pod Preset对象为Pod注入特定的信息,比如Configmap、Secret、存储卷、卷挂载、环境变量等。有了Pod Preset对象,Pod模板的创建就不需要为每个模板显示提供所有信息。
基于预定的期望状态和各个节点的资源可用性,Master会把Pod对象调度至选定的工作节点上运行,工作节点从指向的镜像仓库进行下载镜像,并在本地的容器运行时环境中启动容器。Master会将整个集群的状态保存在etcd中,并通过API Server共享给集群的各个组件和客户端。
Pause容器
每个Pod都有一个特殊的被称为“根容器”的Pause 容器。 Pause容器对应的镜像属于Kubernetes平台的一部分,除了Pause容器,每个Pod还包含一个或者多个紧密相关的用户业务容器。
为什么要有pause容器呢?主要有以下两个原因
在一组容器作为一个单元的情况下,难以对整体的容器简单地进行判断及有效地进行行动。比如,一个容器死亡了,此时是算整体挂了么?那么引入与业务无关的Pause容器作为Pod的根容器,以它的状态代表着整个容器组的状态,这样就可以解决该问题。
Pod里的多个业务容器共享Pause容器的IP,且共享Pause容器挂载的Volume,这样简化了业务容器之间的通信问题,也解决了容器之间的文件共享问题。
Pause容器,又叫Infra容器。我们检查node节点的时候会发现每个node上都运行了很多的pause容器,例如如下:
1 | [root@k8s-node01 ~]# docker ps |grep pause |
pause容器主要为每个业务容器提供以下功能:
- 在pod中担任Linux命名空间共享的基础;
- 启用pid命名空间,开启init进程。
如下我们手动创建一个pause容器,并将nginx和ghost容器加入共享Linux命名空间:
1 | [root@k8s-node01 ~]# docker run -d --name pause -p 8880:80 k8s.gcr.io/pause:3.1 |
现在访问http://192.168.11.129:8880/就可以看到ghost博客的界面了。如下进行解析:
pause容器将内部的80端口映射到宿主机的8880端口,pause容器在宿主机上设置好了网络namespace后,nginx容器加入到该网络namespace中,我们看到nginx容器启动的时候指定了--net=container:pause,ghost容器同样加入到了该网络namespace中,这样三个容器就共享了网络,互相之间就可以使用localhost直接通信,--ipc=contianer:pause --pid=container:pause就是三个容器处于同一个namespace中,init进程为pause,这时我们进入到ghost容器中查看进程情况。
1 | [root@k8s-node01 ~]# docker exec -it ghost /bin/bash |
在ghost容器中同时可以看到pause和nginx容器的进程,并且pause容器的PID是1。而在kubernetes中容器的PID=1的进程即为容器本身的业务进程。
Init容器
init容器在普通容器启动前顺序执行。如果init容器失败,则认为pod失败,K8S会根据pod的重启策略来重启这个容器,直到成功。如果 Pod 对应的 restartPolicy 为 Never,它不会重新启动。
init容器需要在pod.spec中的initContainers数组中定义(与pod.spec.containers数组相似)。init容器的状态在.status.initcontainerStatus字段中作为容器状态的数组返回(与status.containerStatus字段类似)。init容器支持普通容器的所有字段和功能,除了readinessprobe。
Pod的创建
Pod在设计支持就不是作为持久化实体的。在调度失败、节点故障、缺少资源或者节点维护的状态下都会死掉会被驱逐。
通常,用户不需要手动直接创建Pod,而是应该使用controller(例如Deployments),即使是在创建单个Pod的情况下。Controller可以提供集群级别的自愈功能、复制和升级管理。
Pod是Kubernetes的基础单元,了解其创建的过程,更有助于理解系统的运作。
①用户通过kubectl或其他API客户端提交Pod Spec给API Server。
②API Server尝试将Pod对象的相关信息存储到etcd中,等待写入操作完成,API Server返回确认信息到客户端。
③API Server开始反映etcd中的状态变化。
④所有的Kubernetes组件通过”watch”机制跟踪检查API Server上的相关信息变动。
⑤kube-scheduler(调度器)通过其”watcher”检测到API Server创建了新的Pod对象但是没有绑定到任何工作节点。
⑥kube-scheduler为Pod对象挑选一个工作节点并将结果信息更新到API Server。
⑦调度结果新消息由API Server更新到etcd,并且API Server也开始反馈该Pod对象的调度结果。
⑧Pod被调度到目标工作节点上的kubelet尝试在当前节点上调用docker engine进行启动容器,并将容器的状态结果返回到API Server。
⑨API Server将Pod信息存储到etcd系统中。
⑩在etcd确认写入操作完成,API Server将确认信息发送到相关的kubelet。
Pod的终止
因为Pod作为在集群的节点上运行的进程,所以在不再需要的时候能够优雅的终止掉是十分必要的(比起使用发送KILL信号这种暴力的方式)。用户需要能够发送删除请求,并且知道它们何时会被终止,是否被正确的删除。
用户想终止程序时发送删除pod的请求,在pod可以被强制删除前会有一个宽限期,会发送一个TERM请求到每个容器的主进程。一旦超时,将向主进程发送KILL信号并从API Server中删除。如果kubelet或者container manager在等待进程终止的过程中重启,在重启后仍然会重试完整的宽限期。具体流程如下:
- 用户发送删除pod的命令,默认宽限期是30秒;
- 在Pod超过该宽限期后API server就会更新Pod的状态为“dead”;
- 在客户端命令行上显示的Pod状态为“terminating”;
- 跟第三步同时,当kubelet发现pod被标记为“terminating”状态时,开始停止pod进程:
- 如果在pod中定义了preStop hook,在停止pod前会被调用。如果在宽限期过后,preStop hook依然在运行,第二步会再增加2秒的宽限期;
- 向Pod中的进程发送TERM信号;
- 跟第三步同时,该Pod将从该service的端点列表中删除,不再是replication controller的一部分。关闭的慢的pod将继续处理load balancer转发的流量;
- 过了宽限期后,将向Pod中依然运行的进程发送SIGKILL信号而杀掉进程。
- Kublete会在API server中完成Pod的的删除,通过将优雅周期设置为0(立即删除)。Pod在API中消失,并且在客户端也不可见。
kubectl delete命令支持 —grace-period=--force 和 --grace-period=0 来强制删除pod。
Pod的强制删除是通过在集群和etcd中将其定义为删除状态。当执行强制删除命令时,API server不会等待该pod所运行在节点上的kubelet确认,就会立即将该pod从API server中移除,这时就可以创建跟原pod同名的pod了。这时,在节点上的pod会被立即设置为terminating状态,不过在被强制删除之前依然有一小段优雅删除周期。
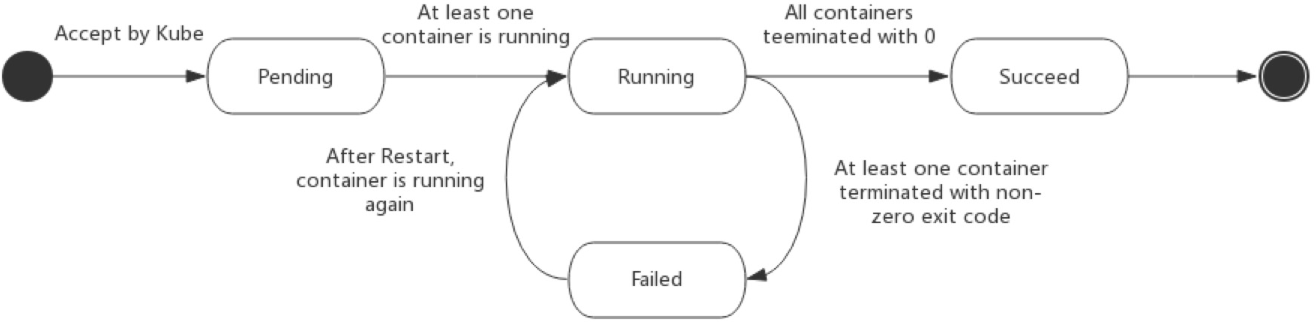
Pod的状态
- 挂起(Pending):API Server创建了Pod资源对象并已经存入了etcd中,但是它并未被调度完成,或者仍然处于从仓库下载镜像的过程中。
- 运行中(Running):Pod已经被调度到某节点之上,并且所有容器都已经被kubelet创建完成。
- 成功(Succeeded):Pod 中的所有容器都被成功终止,并且不会再重启。
- 失败(Failed):Pod 中的所有容器都已终止了,并且至少有一个容器是因为失败终止。也就是说,容器以非0状态退出或者被系统终止。
- 未知(Unknown):因为某些原因无法取得 Pod 的状态,通常是因为与 Pod 所在主机通信失败。
Pod的存活性探测
在pod生命周期中可以做的一些事情。主容器启动前可以完成初始化容器,初始化容器可以有多个,他们是串行执行的,执行完成后就推出了,在主程序刚刚启动的时候可以指定一个post start 主程序启动开始后执行一些操作,在主程序结束前可以指定一个 pre stop 表示主程序结束前执行的一些操作。在程序启动后可以做两类检测 liveness probe(存活性探测) 和 readness probe(就绪性探测)。如下图:
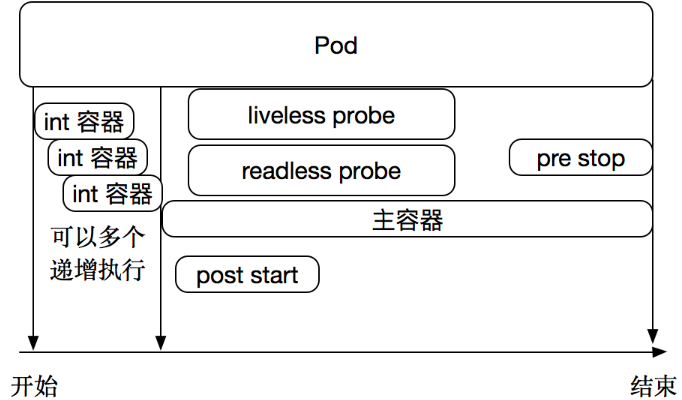
探针是由 kubelet 对容器执行的定期诊断。要执行诊断,kubelet 调用由容器实现的Handler。其存活性探测的方法有以下三种:
- ExecAction:在容器内执行指定命令。如果命令退出时返回码为 0 则认为诊断成功。
- TCPSocketAction:对指定端口上的容器的 IP 地址进行 TCP 检查。如果端口打开,则诊断被认为是成功的。
- HTTPGetAction:对指定的端口和路径上的容器的 IP 地址执行 HTTP Get 请求。如果响应的状态码大于等于200 且小于 400,则诊断被认为是成功的。
livenessProbe解析
1 | [root@k8s-master ~]# kubectl explain pod.spec.containers.livenessProbe |
设置exec探针举例:
1 | apiVersion: v1 |
上面的资源清单中定义了一个Pod对象,基于busybox镜像启动一个运行“touch/tmp/healthy;sleep60;rm-rf/tmp/healthy;sleep600”命令的容器,此命令在容器启动时创建/tmp/healthy文件,并于60秒之后将其删除。存活性探针运行“test-e/tmp/healthy”命令检查/tmp/healthy文件的存在性,若文件存在则返回状态码0,表示成功通过测试。
设置HTTP探针举例:
1 | apiVersion: v1 |
上面清单文件中定义的httpGet测试中,请求的资源路径为“/healthy”,地址默认为PodIP,端口使用了容器中定义的端口名称HTTP,这也是明确为容器指明要暴露的端口的用途之一。
设置TCP探针举例:
1 | apiVersion: v1 |
上面的资源清单文件,向Pod IP的80/tcp端口发起连接请求,并根据连接建立的状态判断Pod存活状态。
每次探测都将获得以下三种结果之一:
- 成功:容器通过了诊断。
- 失败:容器未通过诊断。
- 未知:诊断失败,因此不会采取任何行动。
Kubelet 可以选择是否执行在容器上运行的两种探针执行和做出反应:
- livenessProbe:指示容器是否正在运行。如果存活探测失败,则 kubelet 会杀死容器,并且容器将受到其 重启策略 的影响。如果容器不提供存活探针,则默认状态为
Success。 - readinessProbe:指示容器是否准备好服务请求。如果就绪探测失败,端点控制器将从与 Pod 匹配的所有 Service 的端点中删除该 Pod 的 IP 地址。初始延迟之前的就绪状态默认为
Failure。如果容器不提供就绪探针,则默认状态为Success。
livenessProbe和readinessProbe使用场景
如果容器中的进程能够在遇到问题或不健康的情况下自行崩溃,则不一定需要存活探针; kubelet 将根据 Pod 的restartPolicy 自动执行正确的操作。
如果希望容器在探测失败时被杀死并重新启动,那么请指定一个存活探针,并指定restartPolicy 为 Always 或 OnFailure。
如果要仅在探测成功时才开始向 Pod 发送流量,请指定就绪探针。在这种情况下,就绪探针可能与存活探针相同,但是 spec 中的就绪探针的存在意味着 Pod 将在没有接收到任何流量的情况下启动,并且只有在探针探测成功后才开始接收流量。
如果您希望容器能够自行维护,您可以指定一个就绪探针,该探针检查与存活探针不同的端点。
请注意,如果您只想在 Pod 被删除时能够排除请求,则不一定需要使用就绪探针;在删除 Pod 时,Pod 会自动将自身置于未完成状态,无论就绪探针是否存在。当等待 Pod 中的容器停止时,Pod 仍处于未完成状态。
Pod的重启策略
PodSpec 中有一个 restartPolicy 字段,可能的值为 Always、OnFailure 和 Never。默认为 Always。 restartPolicy 适用于 Pod 中的所有容器。restartPolicy 仅指通过同一节点上的 kubelet 重新启动容器。失败的容器由 kubelet 以五分钟为上限的指数退避延迟(10秒,20秒,40秒…)重新启动,并在成功执行十分钟后重置。pod一旦绑定到一个节点,Pod 将永远不会重新绑定到另一个节点。
资源需求和资源限制
在Docker的范畴内,我们知道可以对运行的容器进行请求或消耗的资源进行限制。而在Kubernetes中,也有同样的机制,容器或Pod可以进行申请和消耗的资源就是CPU和内存。
CPU属于可压缩型资源,即资源的额度可以按照需求进行收缩。而内存属于不可压缩型资源,对内存的收缩可能会导致无法预知的问题。
资源的隔离目前是属于容器级别,CPU和内存资源的配置需要Pod中的容器spec字段下进行定义。其具体字段,可以使用”requests”进行定义请求的确保资源可用量。也就是说容器的运行可能用不到这样的资源量,但是必须确保有这么多的资源供给。而”limits”是用于限制资源可用的最大值,属于硬限制。
在Kubernetes中,1个单位的CPU相当于虚拟机的1颗虚拟CPU(vCPU)或者是物理机上一个超线程的CPU,它支持分数计量方式,一个核心(1core)相当于1000个微核心(millicores),因此500m相当于是0.5个核心,即二分之一个核心。内存的计量方式也是一样的,默认的单位是字节,也可以使用E、P、T、G、M和K作为单位后缀,或者是Ei、Pi、Ti、Gi、Mi、Ki等形式单位后缀。
资源需求举例:
1 | apiVersion: v1 |
上面的配置清单中,nginx请求的CPU资源大小为200m,这意味着一个CPU核心足以满足nginx以最快的方式运行,其中对内存的期望可用大小为128Mi,实际运行时不一定会用到这么多的资源。考虑到内存的资源类型,在超出指定大小运行时存在会被OOM killer杀死的可能性,于是该请求值属于理想中使用的内存上限。
资源限制举例:
容器的资源需求只是能够确保容器运行时所需要的最少资源量,但是并不会限制其可用的资源上限。当应用程序存在Bug时,也有可能会导致系统资源被长期占用的情况,这就需要另外一个limits属性对容器进行定义资源使用的最大可用量。CPU是属于可压缩资源,可以进行自由地调节。而内存属于硬限制性资源,当进程申请分配超过limit属性定义的内存大小时,该Pod将会被OOM killer杀死。如下:
1 | [root@k8s-master ~]# vim memleak-pod.yaml |
Pod资源默认的重启策略为Always,在memleak因为内存限制而终止会立即重启,此时该Pod会被OOM killer杀死,在多次重复因为内存资源耗尽重启会触发Kunernetes系统的重启延迟,每次重启的时间会不断拉长,后面看到的Pod的状态通常为”CrashLoopBackOff”。
这里还需要明确的是,在一个Kubernetes集群上,运行的Pod众多,那么当节点都无法满足多个Pod对象的资源使用时,是按照什么样的顺序去终止这些Pod对象呢??
Kubernetes是无法自行去判断的,需要借助于Pod对象的优先级进行判定终止Pod的优先问题。根据Pod对象的requests和limits属性,Kubernetes将Pod对象分为三个服务质量类别:
- Guaranteed:每个容器都为CPU和内存资源设置了相同的requests和limits属性的Pod都会自动归属于该类别,属于最高优先级。
- Burstable:至少有一个容器设置了CPU或内存资源的requests属性,单不满足Guaranteed类别要求的资源归于该类别,属于中等优先级。
- BestEffort:未对任何容器设置requests属性和limits属性的Pod资源,自动归于该类别,属于最低级别。